AI’s the big thing now, and within that field, the representation of the “giantess” is both intriguing and challenging. A few good AI engines came out capable of depicting this unique subject, some less impressive competitors arose, and everyone has been upping their game ever since in the world of “giantess” creation. Pixiv even warned artists to tag their AI-created giantess artwork, building a function to accommodate this growing phenomenon.
First thing to note: Most free AI programs are built to reject NSFW content, and this can affect those seeking to depict the “giantess” theme. Some programs have a blacklist of terms they won’t allow for processing, including “giantess,” while others render the image but may blur or remove explicit depictions.
Second note: I’m only using free AI programs for my “giantess” explorations. I see other artists paying for accounts and creating brilliant, gorgeous material. While I may not create such high-level content, I’m eager to see how close I can come in portraying the giantess figure.
Third note: Most programs are baffled by the term “giantess.” Once in a while, I can work around it with terms like “tall woman” or “gigantic woman,” but generally, AI can’t wrap its mind around the complex and fascinating concept of a “giantess.” This shows the need for more innovation and understanding within AI to fully grasp and visually represent the nuanced idea of a “giantess.”
I’m using the prompt: “a beautiful giantess strides through a tiny village, detailed, realistic” to compare these programs. I’ll only use a filter if there’s no option not to.
DALL-E | ERNIE-ViLG | Craiyon | neural.love
starry.ai | NightCafe | Artbreeder | DeepAI | Fotor
Dream.ai by WOMBO | Photosonic | Perchance
Stable Diffusion 2-1 | DreamStudio | Hotpot
Midjourney | BlueWillow | Runway | Pixlr | OpenAI
Wonder | Lisa AI | AIBY | Jasper | Maze Guru
Adobe Firefly
DALL-E
I think DALL-E was the first AI art program to break headlines. It wasn’t easily accessible: you had to sign up on the waitlist, and the moderators would examine your online presence to determine whether you were going to try to make porn, which disqualified you from an account. Now anyone can use DALL-E, but DALL-E 2 is locked down. There were a few competitors but their output was comparatively trash, and DALL-E was producing excellent work.






With the prompt I requested four variation images. The first two images above came from the first process, and I thought they were great. They looked like plasticine models, but they still did a lot of things right. I ran variations of the second image, then of the best of the four successive variations. Each of the four following images represents the best of the next four iterations, and they seemed to get progressively worse.
I decided to build variations from the first image and ran four more iterations, selecting the best of each group.




It looks like it can’t get away from the idea of a Claymation village. It refined the giantess to look a little more lifelike, but it also shrank her. DALL-E’s prompts are entirely text-driven, whereas other programs offer controls to guide how close the program adheres to what you’re asking and how wildly it can deviate from a prompt image.
ERNIE-ViLG
ERNIE-ViLG, provided by Hugging Face and PaddleHub, is a Chinese program, which presents the additional hurdle of translating my prompt into Chinese before interpreting the prompt for an image. It seems that Chinese does have a word for giantess, 女巨人, so maybe it’ll understand what I mean.


ERNIE-ViLG does seem to grasp the concept of a larger-than-normal woman, and “village” translated well. Still, the images are not ideal, but there’s no way to upload an image to assist with the text prompt. All I can do is run the same prompt again and hope for different results. Like many AI art programs, ERNIE-ViLG offers the option of setting an artistic filter from a dropdown menu before processing. By default it’s set to “explore infinity,” which I guess just means “random”; for the next two images I set it to “conceptual art,” as I didn’t need to see it as a watercolor or vaporware.


These are actually lovely. Not what I had in mind, but my prompt was purposely vague, both to grant the AI greater creative liberty and not to bog it down with complicated details.
Craiyon
Right after DALL-E came out, this company built what they called DALL-E Mini and earned themselves a cease-and-desist, so now they’re Craiyon. They offer no controls beyond text prompts, but they do generate nine sample images.




These are unacceptable, and these are the least abstract out of the nine given images. Unlike with other AI art programs, there is no option here to select an image and generate further variations on it. Or I don’t think so: to test this, I opened one image and hit the button to run the text prompt again. Would the next images seem like variants of the first?




Not at all. The imagery here looks less abstract than the first round, but none of the next nine images looked like a reinterpretation of the first visual prompt. It’s just a craps shoot every time.
neural.love
Neural.love is one of those AI programs that gives you all sorts of controls to guide the output. By that I mean, after you’ve entered your text prompt, you can select an artistic style, set processing cycles, select how close you want it to stick to your prompt, upload an image for it to riff on, and enter negative prompts, things you don’t want to see in the finished product (blurring, missing limbs, etc.). After selecting Midjourney style, I left all the defaults on: a square image, four sample images; some of the options require you to purchase credits if you want to implement them.




These are lovely images, and neural.love certainly grasps the concept of a village. Are they Midjourney style? I was expecting something different. Also, this program offers the smallest sample images so far, 512×512.
At the very least I was expecting something resembling a giantess, and in this neural.love thoroughly fails the test.
starry.ai
starry.ai starts you out with four different AI engines, one of which is about to be deprecated. I went with the basic model, Argo, just to keep things simple. From there, I get the options to select an artistic style, add a visual prompt, determine the number of variations. Processing images costs credits, but you’re given a small number of credits and you can earn a few by logging in daily.




This program also is very clear on what a village looks like, but as a bonus it bothered to make the village look miniature through a tilt-shift effect. The structures look more realistic than clay sculpture, which is also welcome. However, out of four images, only one seemed to recognize what a giantess looks like. Now I have the chance to highlight this image and click “evolve,” to directly generate four more iterations of the most successful image. This takes me back to the options screen, with this image preloaded as a visual prompt.
UPDATE: Starry AI figured out what giantesses are!




Starry AI reorganized its program models, which was a rude surprise at first. I’d been using Argo, and suddenly Argo started putting out hideous mutations. It couldn’t correctly interpret anything I asked of it. I noticed that they offered a new option called Lyra, and this was putting out quality renders in any of its models (3D figure, anime, portrait, “woolitize” (makes everything look crocheted), etc.).
I tried the basic prompt in the basic Lyra style, and I got the first two images: kinda tall women heading into a town not built for them. But when I switched to anime style… suddenly the program knew what a gigantic woman should look like! Pulling from a different database of reference material, I guess. As of this writing, Starry AI has further reorganized itself into two modes, Art and Photo (for realistic images), and Art offers all the features Lyra used to. If you select Photo, then you get a plethora of options: Popular (Artstation, Pixiv, DeviantArt, etc.), In the Style of (ripping off popular, living artists), Movements (Impressionism, Art Deco, Cubism, etc.), Made of (wire, mist, crystal, iron, etc.), and Medium (chalk, pencil, watercolor, etc.). Wow.
Which doesn’t make sense, since those are digital art styles, and Photo is supposed to be photorealistic. It feels like those effects are wasted on the photo aspect, and having run some other prompts through it, I don’t see what those styles are adding to the photo. For that matter, I entered “watercolor” and the engine ignored that prompt completely.
NightCafe
This program also hosts several AI engines, most notably Stable Diffusion and DALL-E 2. I’m using Stable Diffusion for this, and then I get more options: after entering the text prompt, I click on negative modifiers, then on “let me tweak it” and I’m given an excellent set of clarifying prompts to clean up the image: “ugly, tiling, poorly drawn hands, poorly drawn feet, poorly drawn face, out of frame, extra limbs, disfigured, deformed, body out of frame, blurry, bad anatomy, blurred, watermark, grainy, signature, cut off, draft.” I’m leaving those as-is because I couldn’t do better myself.
NightCafe is another credit-based program, but again, you can login once a day to gain free credits. And again, if you leave all settings alone it costs one credit to run, and more options can reduce or increase that cost. Additionally, if your prompt turns up something NSFW, the program will reimburse you one-quarter credit per unusable image. (But of course, we want those…)




NightCafe doesn’t know how to parse “giantess,” it seems. None of these images are suitable for evolving. Each scene looks like a realistic diorama with injection-molded plastic figurines. One might expect an HO scale train to come tootling through any minute. Note the third image: NightCafe offers you the option of including an “artist overlay,” equivalent to a watermark with your information on it for promotion.
Artbreeder
Artbreeder seems to specialize in modifying existing artwork. When you want to start a new project, it asks if you want the “splicer” or “collager.” I chose splicer and was presented with an art style menu; selected “general.” The next screen gave me a random image, which I won’t use, and presents the option to upload an image to start working with. There is no option in splicer to enter a text prompt. Collager is what it sounds like: you can upload and draw shapes and images to start working with, and then Artbreeder’s AI engine will modify these into a coherent image, along with your text prompt. Oh well, I’m game: I’ll search for and modify some components for my image.

Great: I found a woman and I found a village. Now I’ll enter “a beautiful giantess strides through a tiny village, detailed, realistic” and see what it does with that. It’s offering me 15 renders: that’s generous and fun, but I’ll cut it down to six and I’ll slide the AI intensity down to about half. (Note: It was not offering 15 images. This must be a processing factor, because it only produced one crappy image.)
After a couple false starts (I didn’t realize you need to fit all your components into a tiny little box, when you have the whole big wide screen to play with), this is what it came up with:

Clearly, working with Artbreeder requires considerable investment in learning the tools. And yet, if you search for #giantess, you can see a gallery of other artists’ astounding work. I’m guessing those are from paid accounts, and those artists have probably put in their 10,000 hours to figure this shit out.
UPDATE: I did figure it out. I kept coming back to Artbreeder, poking around, clicking things and paying attention, and eventually I figured out how to generate AI art with it. I ran my sample prompt recipe into it, and here’s what it produced.




In two out of four trials, it seemed to understand that “giantess” means “a taller than usual woman.” Can’t get away from the plasticine miniature appearance, at least with this limited prompt, but with these results Artbreeder is at least placed on par with DALL-E, Starry.ai, NightCafe, Runway, and DreamStudio, and still better than Craiyon, Dream by WOMBO, and Pixlr.
So, I apologize to Artbreeder! I simply didn’t understand you.
DeepAI
There we go, back to text prompts. Below that text field are a few rows of icons representing image styles like fantasy world, old style, renaissance painting, architectural, logo generator, etc. About half of these are locked and reserved for paid accounts, that’s fair. I’m entering my prompt and choosing the fantasy world generator.
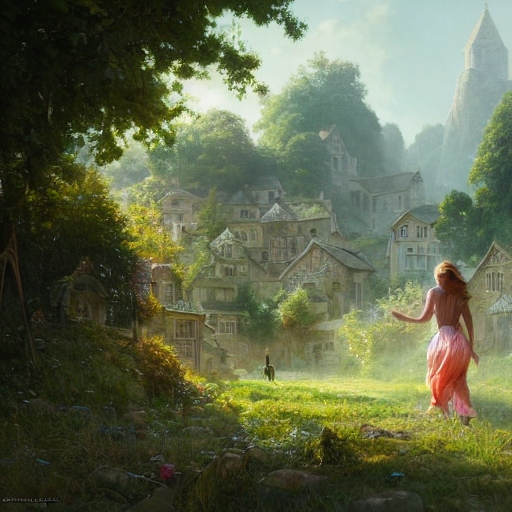
That’s a pretty robust village, but there’s nothing to suggest she’s a giantess. You only get the text prompt and the artistic style to modify, no other controls, and you only get one image at a time. But you can see what other people are doing, and I see someone else is trying something similar, with at least as much frustration.




It’s very far from a perfect science.
Fotor
Fotor is another “you supply the materials, we’ll play around with them” program. To me, this process is easier than Artbreeder’s: using the stock materials from the Artbreeder project, I was able to remove the background on the woman completely. There are all sorts of other filters and effects to use, but now I’m just going to go down to their AI Art tab and select HDR Photography Technology and apply—
Oh. That’s not how that works. Well, I have a basic collage, but can’t they interpret that somehow? Not really. Another option in the AI Art tab is GoArt – NFT Creator. I have nothing to do with NFT bullshit, but this option is closer to what I want. In practice it functions exactly like the Prisma app: it puts an artistic filter on your image. So you apply the filter to your image…
Wait, no, that doesn’t work. It only filtered the background because the program didn’t flatten the two layers (woman and village). Then I’ll just download the composite and reupload it for the filter… oops, no, you have to pay to download. Liking this less and less. The obvious way around this is to take a screenshot and reupload that to apply an artistic filter.

There, a crappy image I had to build myself, complete with their watermark, and absolutely no AI involved. Fotor misrepresents itself to be found when you’re searching for AI programs, but really it’s a substandard Pixlr/Prisma mashup.
UPDATE: I found the option to generate AI art. When I was a beginner, I couldn’t find this function in Artbreeder and Fotor, and now that I know a little more and can read into poor UX, I’m able to figure out what they mean.
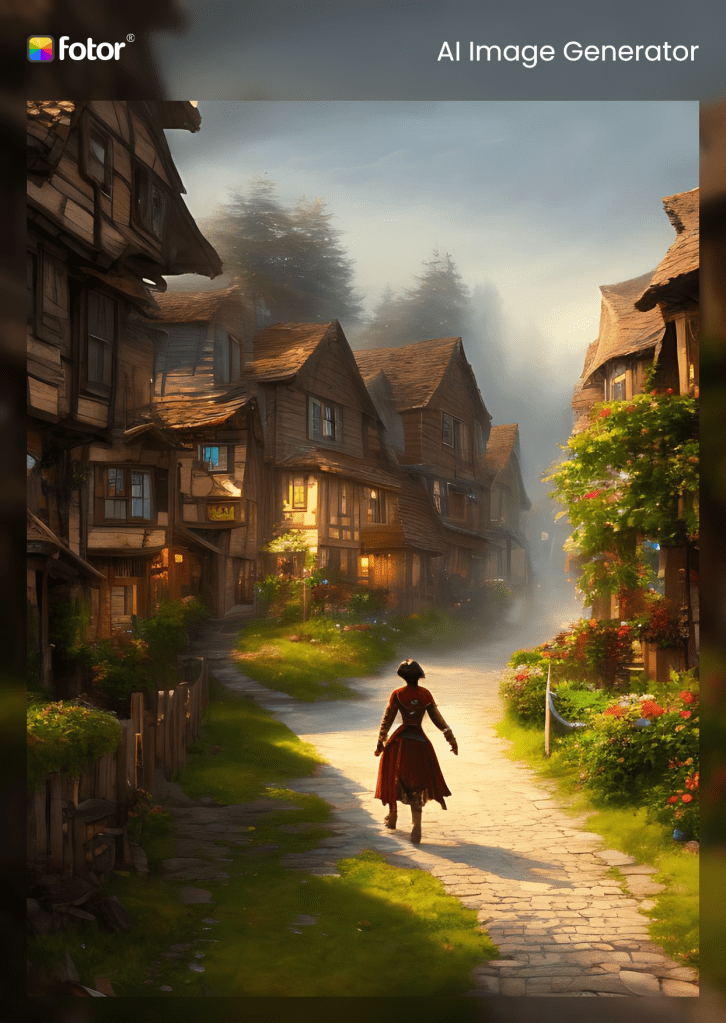


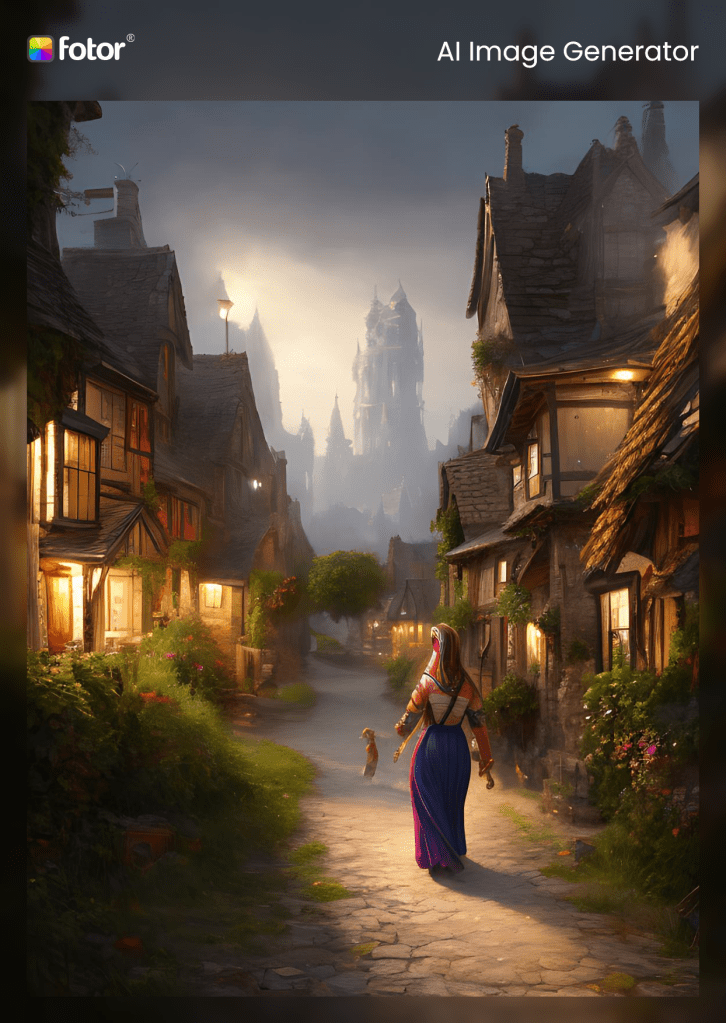
It still doesn’t matter, because Fotor doesn’t know what a giantess is. It avoided the plasticene setting, however, and created four dreamy fantasy themes of four interesting-looking women walking into a village. See, it gets most of it right, it just hasn’t been fully educated and doesn’t know what this one crucial element could mean. The images are lovely, and the output is 1244×1754, which is among the largest resolution in this whole selection. I bet it’s a pretty good program for most other people.
Dream.ai by WOMBO
At this point I started getting tired. I entered my text, I selected “no style.”
There, a beautiful “trading card” with the option to mint as an NFT or even print onto a canvas. Because who wouldn’t want this timeless beauty?
Photosonic
As soon as I entered my prompt, it immediately pulled up a large catalog of similar prompts (as long as I’m not logged in). If I don’t feel like trying to develop my own image from scratch, I can riff on someone else’s product or just study their prompt terms. But no, when I logged in, I found I had eight credits to play with so I’m going back to my original terms and selecting fantasy style.
The program keeps telling me to turn off my ad blocker. That for sure is not happening.


Once again, no problem parsing “village.” The first one shows a really tall girl in something like a tennis outfit, and the second just has… what, a paper cutout of a woman walking down a miniature village? That might be fun reference material for making my own paper village, like for a rainy day project, but I’m just not confident that Photosonic knows what a giantess is. There’s an option to enhance each image, but that’s just so you can download an HD version of the same image.
Perchance
I found Perchance by accident. It’s free, but it requires you to disable your ad blocker. That’s okay, because it gives you a large workspace with unobtrusive ads at the bottom, and it needs those ads to sustain itself, so why not.
Perchance has a simple interface: enter what you want to see, enter what you don’t want to see, pick your filter. You’ll have to play around a lot to figure out what styles and filters you like, but that’s fine because Perchance produces quality work very rapidly. Unfortunately, it only puts out small images, 512×768, with no option to enlarge, only to choose between portrait, landscape, or square. There’s no way to make it refer to a previous image, and no way to weight the source image or even your prompts. Well, it’s free.






Perchance seems to know what a giantess is supposed to be, most of the time. It depends on the filter, and it helps to create the illusion by adding “low-angle shot” to the prompt, but it can produce some interesting designs in a very wide variety of styles. So, it doesn’t offer some features, but it does other things very well. It’s a good time-sink.
Stable Diffusion 2-1
Back to Hugging Face (see ERNIE-ViLG) for their own Stable Diffusion! I’ve entered the usual text prompt, and they have negative prompts so I’m grabbing that from what NightCafe offered, and I’m not messing with the advanced options, which is only a guidance scale. I’ve tried enough of these programs that it probably just weights how close it should stick to the prompt.
I got an error. I’m trying it again without the negative prompts, in case that confused it.
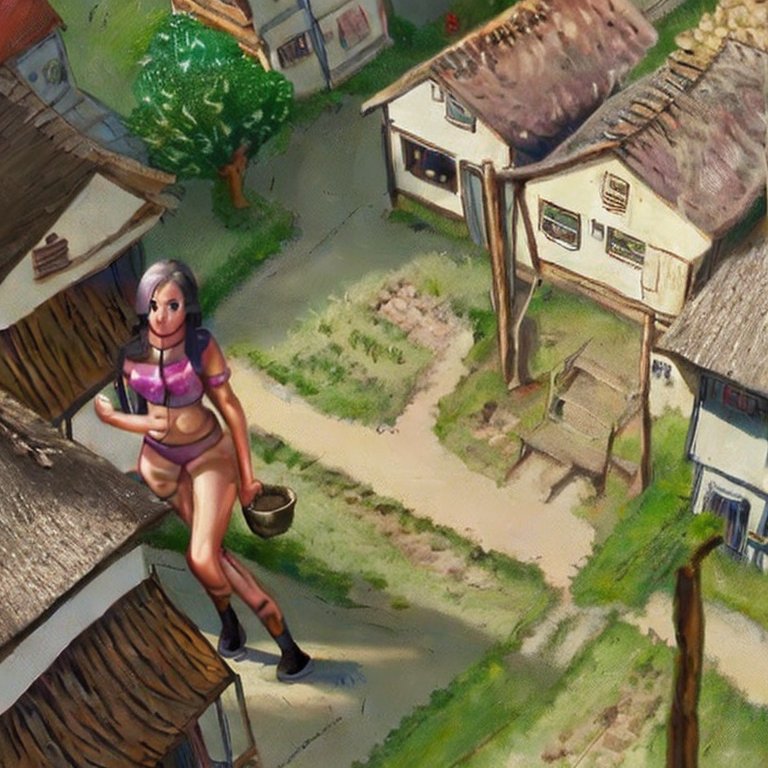
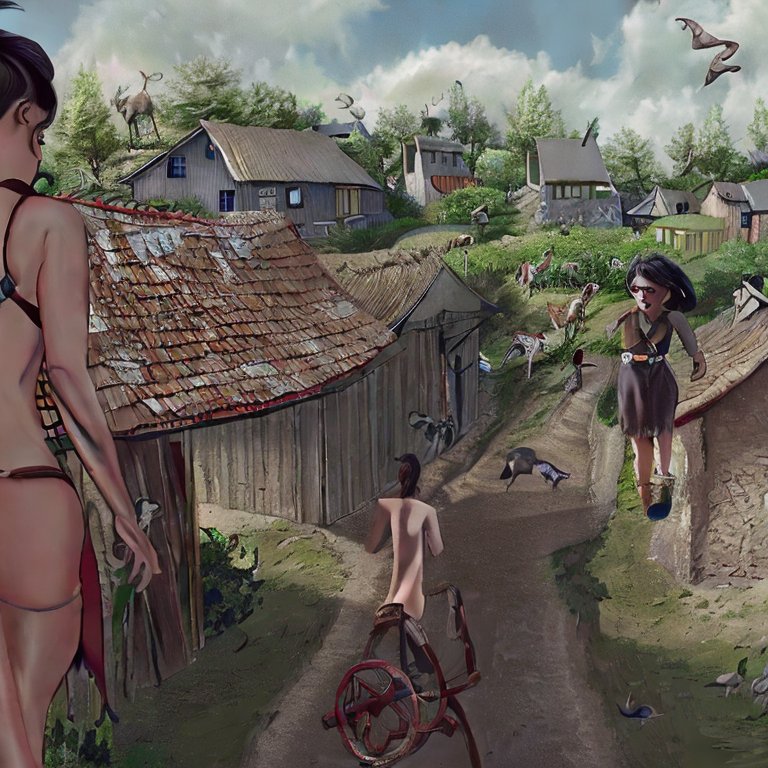
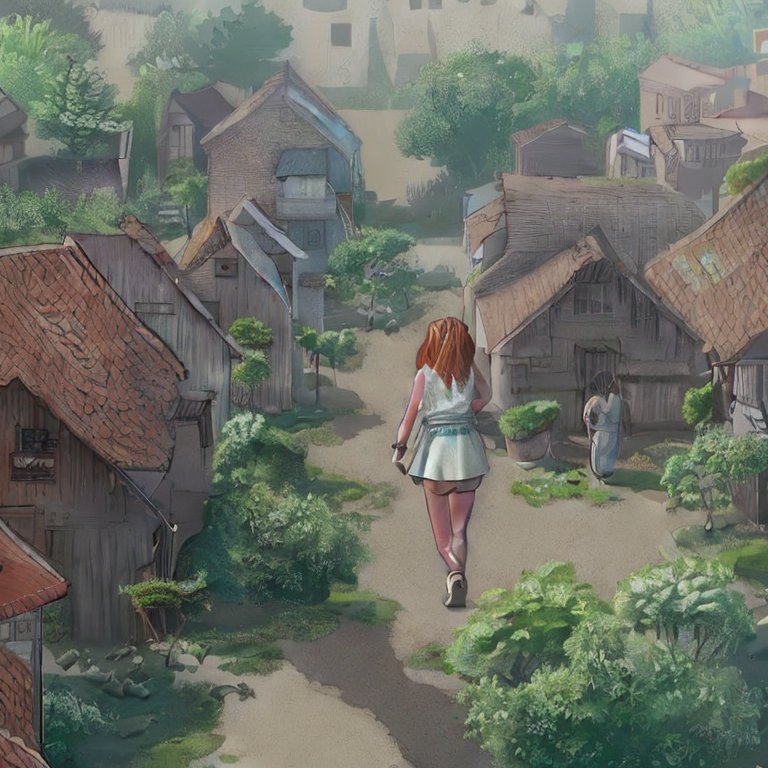
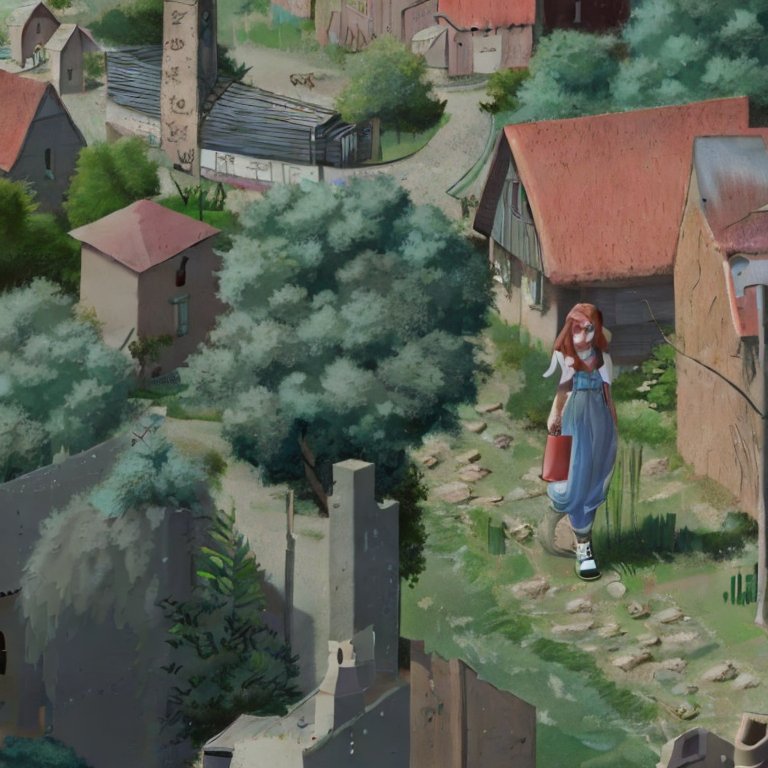
These… aren’t the worst I’ve seen. I like the unasked-for artistic filter, and it kinda sorta seems like it can figure out what an unrealistically tall woman could look like. From here I can select the image I like (the first one) and rerun the prompt.
And it looks like the error message I didn’t read was simply that the service was busy. My bad! I should’ve kept the negative prompts.
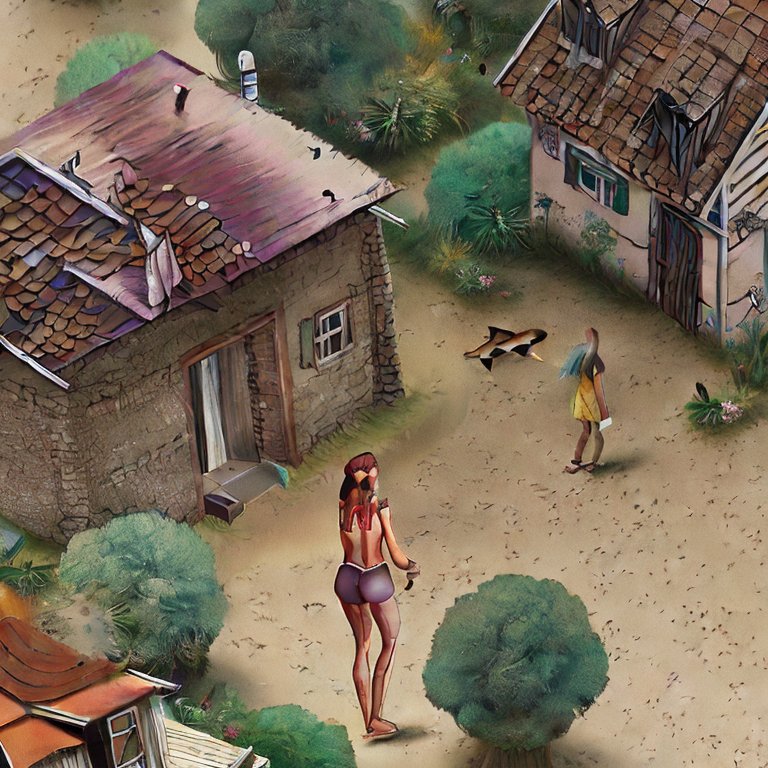
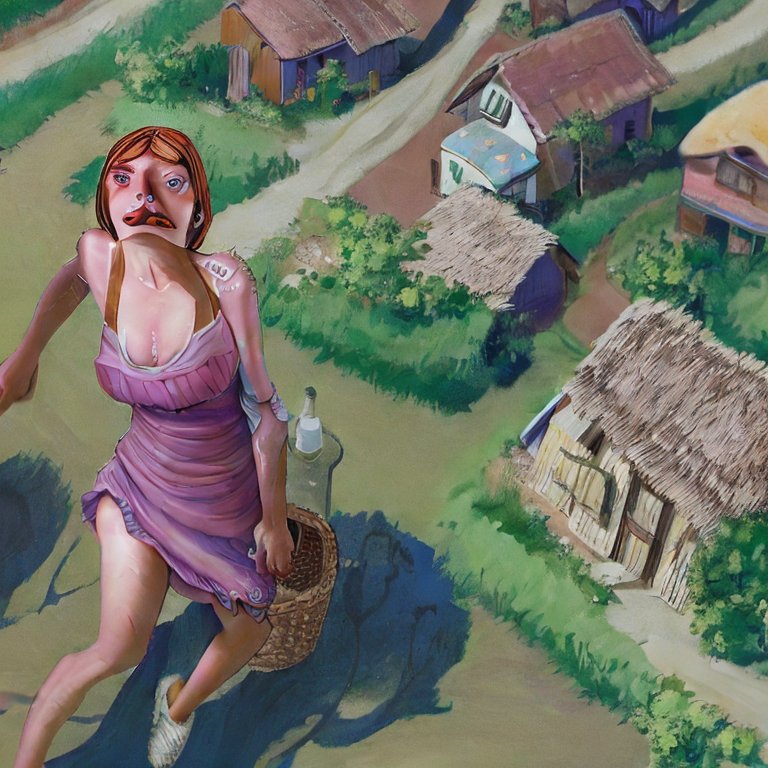


And we’ve waded back into “stuff of nightmares” territory. What if I reran that first image with the negative prompts?
Damn, I can’t go back, and if I start over I can’t reload the first image. Oh well. I’m entering the usual prompt and including the negative prompt.




Not awful! The negative prompts seemed (perhaps coincidentally) to bring the images closer to the prompts. The first two definitely have promise. Or maybe my standards have lowered by this point.
DreamStudio (beta)
DreamStudio was recommended by Stable Diffusion 2-1 “for faster generation and API access,” though I don’t know what that means. The strange thing about this beta program is that it lets you try a bunch of images while telling you that it’s charging you, though you haven’t given it any credit information. Eventually you run out and it tells you your balance is outstanding, but it doesn’t ask you for a payment method. Confusing.
Anyway, you can type in text prompts (without negative prompts), and you can upload a starter image, and you can control the size of the output image, how many you want, how much processing it should have done, and how close it should adhere to your text prompt. Elevating those values costs more credits, of course, but let’s see what it can do.




What’s up with that blurred-out image? That’s what many of these AI programs do when they generate something NSFW, usually nudity, but from what I can make out there aren’t even any people in that image. How strange!
Regardless, this program doesn’t readily apprehend the primary qualities of a giantess either, except for in the fourth image where we see something like a superhero twice the height of a villager. Since DreamStudio lets you feed image prompts, let’s see what the evolution of this provides.




Interesting: it help pretty closely to the source material and only tweaked details like the villager’s clothing on the left and the lantern/handbag the titaness is holding. Other than that, it doesn’t seem like a very thoughtful evolution, and even if it’s photorealistic it’s still a tilt-shift of a plastic diorama. It could bear some working on.
Hotpot
Right off the bat, Hotpot advises you to buy credits for faster processing times and larger images. You get five free images per day to play with, but any more than that and you get banned. Wow.
I’ve entered my standard prompt and there are zero options for any modification, not even an artistic filter. True to their word, the processing time is the longest of any of these programs. Hotpot isn’t here to make friends.

And to wrap it all up with a tidy bow, Hotpot has no idea what a giantess looks like, or even a village. However, the loveliness of this image cannot be denied, even if it’s the smallest of all offered (256×256). At least they offer instructions on minting your own NFT. Great job, guys; I won’t be back.
Midjourney
Midjourney produces gorgeous work. It also limits how much you get to play with it, which in a way is reasonable because it is a great service. It’s tied up with Discord, so you actually work within Midjourney’s Discord server (in one of the newbie rooms) to produce and refine your images. I did this for a while, prior to today’s experiments, and was able to trick the program into giving me something close to what I wanted, before it locked me out and demanded recompense.
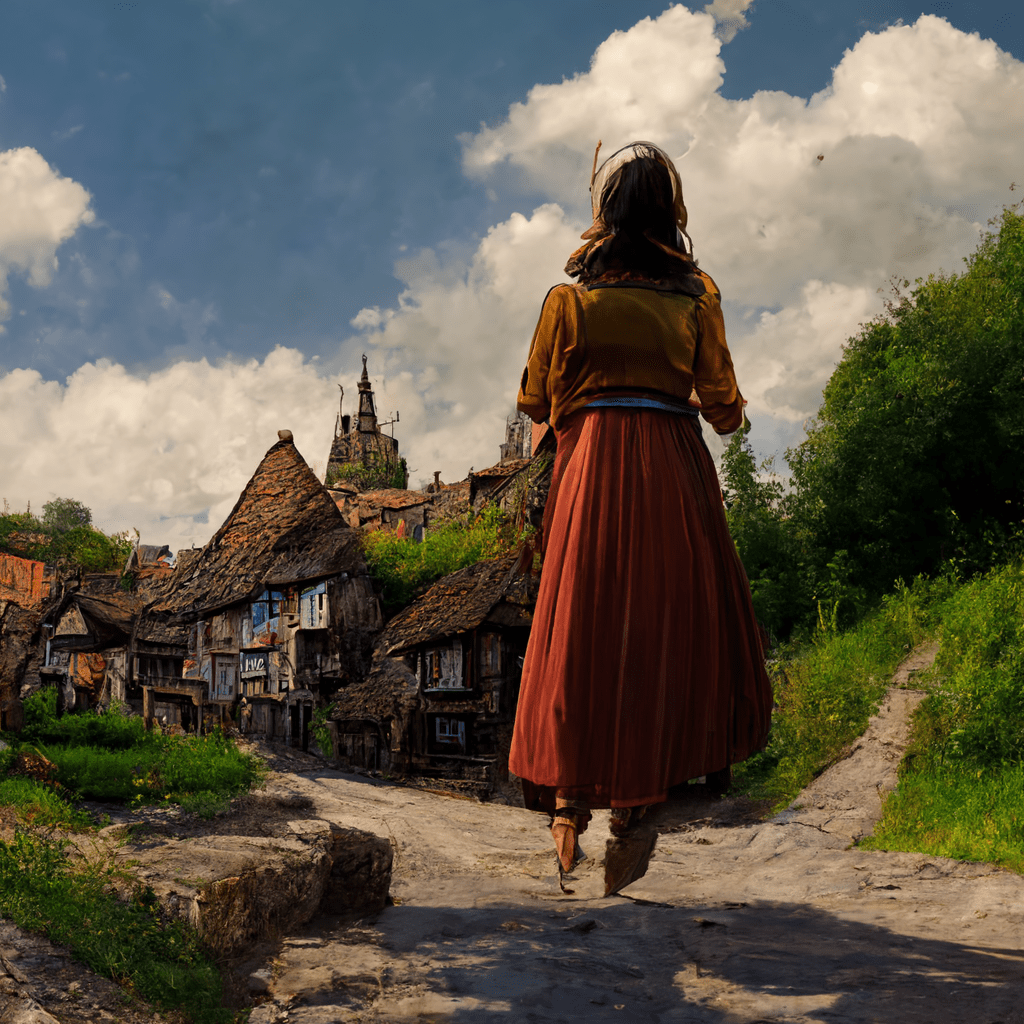


I’d used a slightly different prompt, “a beautiful giantess striding through a tiny medieval village,” and was impressed with what came out. I was more impressed when I refined/evolved these images. It’s an excellent program and I miss it. Plans start at $10 monthly or $8/month yearly.
BlueWillow
Someone noticed my activity on Discord—I joined channels for Midjourney, NightCafe, and Stable Diffusion—and floated me an invite to try out BlueWillow. I’ve played around with it a bit, watching what other, more experienced artists are doing with it. I noticed that they’re very eager to build loyalty: recently they held a recruitment contest and the winner with the most recommendations won US$100, reputedly. That’s a fairly aggressive awareness campaign. Perhaps the users themselves are grooming BlueWillow to develop, evolve, and compete with Midjourney? They do produce beautiful work.
I ran my standard prompt through…






BlueWillow couldn’t parse “giantess” either. When it seemed to come close, I requested variations, but I never achieved success. Because this is a Discord channel (where you just type in /imagine and a sequence of as many prompts as you can stomach), there are no sliders to adjust processing time, to bias closer to your text prompt, or to work closely off the image. On the other hand, and this is a large hand, the images that come out are enormous, 2048×2048. That’s quite generous for a free program! And maybe this is a limited-time run, where it’s free for now but when it’s sufficient developed they’ll lock it down for paid accounts. They haven’t said anything like this, but that’s how things tend to go.
The images are gorgeous and detailed, truly lovely. I just can’t get it to comprehend a very, very, ridiculously tall woman.
Runway
Right off the bat: biggest drawback is that you must use Runway only in the Chrome browser, which means everything you do and type is recorded to sell you material goods or influence your political orientation ever so slightly.
The second thing I noticed was that it seems to be a robust video platform: their demo breezes at breakneck speed through how to wipe out the background of a moving, acting figure in a video clip and plant them, passably, onto another background. That seems really cool, and if I were into video editing in the least way, I might consider trying out their Pro free trial. But I’m not so I won’t.
What Runway has in common with most other AI engines is that it has no freakin’ clue what a giantess might be. I used the basic prompt, selected “photographic” medium, and now I will share with you only the best of what it produced out of 25 free images.




That was the best of the crop. Trust me when I tell you everything else was far off the mark or uglier than what appears here. I’m sure if I asked it to produce a cute dog or sun shining on rolling green hills, it would’ve done just fine. If I would’ve asked it to produce a lovely smiling brunette woman, it would have been on steadier footing. However, most AI engines can’t imagine a larger-than-normal woman and have probably been banned from any forums and databases that store all that material (or wouldn’t select it anyway, as it’s mostly NSFW). So: in terms of creating a realistic, attractive image of a gigantic woman, Runway is better than Craiyon, DreamStudio, Dream by WOMBO, and NightCafe, on par with Starry.ai, and much worse than Midjourney and BlueWillow.
Pixlr
Pixlr is my favorite free graphics editor. I don’t have the technical skill to justify the high subscription fees of Photoshop, and GIMP sneeringly dismisses all concerns about sharing a name with an ableist epithet for disabled people. Pixlr comes in two flavors, based on your skill level, and they’ve rolled out competitive features like background removal and avatar graphics. Very recently they underwent another major update, now offering preformatted image templates for a wide variety of social media platforms, and… AI art! Imagine my surprise!




The bad news is that it’s not a very precise engine. I specified “photography” for the third and fourth images, but they look like paintings or drawings. The good news is that Pixlr’s AI engine knows what the hell a giantess is! How rare is that! With some tweaking and a lot of patience, I could probably produce something very close to sufficient. Unfortunately, you can’t feed an image back into it as a reference, though you can produce variations of any image output.
I included that last image because… what the hell?
UPDATE: Pixlr has constantly been improving itself since last I checked in. It’s got filters, lighting styles, tonalism, lots of toys and tools to play with. And it’s just better.




OpenAI
I don’t even know what OpenAI is capable of. I threw the command at it without even looking at its services or options. I’ve been drinking and I’m kind of jaded and not expecting much out of this random-ass program that seems to persistently offer 500 beginner-credits.






All right, just like many other programs, OpenAI is 50% incapable of interpreting what “giantess” could possibly mean. And though the prompt does not employ “miniature” or “plasticine,” it nonetheless seems fixated on creating cutesy miniature figurines with an inappropriate measure of sexiness. I can’t speak too highly of OpenAI, as it situates itself right in the center of the spectrum between prowess and don’t-give-a-fuck.
Wonder
Wonder is a smartphone app. People say there’s a free version, but I never found it: I gambled on a one-month payment, which was cheaper than most of the engines in this list. It’s very easy to use, it produces beautiful images (though it facilitates emulating living artists, which is on the wrong side of the gray zone), and it… mostly understood what I wanted. Sometimes.






It’s like it really wanted to understand what I was talking about, and it made some brave attempts, but it had gone without sleep for several days and couldn’t see the controls, and things went a little sideways in the execution. Sometimes it really could produce a coherent, gigantic, lovely woman, either towering over the buildings or, in one instance, walking through a crowd of little people. But it was not easy to get it to do that twice, and sometimes the giantess would be missing a leg or get twisted up into one-and-a-half giantesses, or sometimes become disembodied and float several meters above herself while not being terribly big. Wonder does a lot of things right, and it has a long way to go.
Lisa AI
Lisa AI is also a phone-based app. Mostly I work on my workstation, sometimes on a laptop, so I prefer the browser-based AI programs. But it’s worthwhile to see what phone apps are doing, because it’s unfair to rule anything out (unless it’s freakin’ expensive). I put it through the paces to see what it could and couldn’t do—the real test is to determine whether the database it’s been fed recognizes what a giantess is.




Lisa’s pool of resources weren’t sure what a giantess is.
The first two images are what I got with no filter settings, using nothing other than the original prompt recipe. In the second image, we can see the woman is, yeah, taller than normal, but not quite a titaness. The first figure is slightly deformed in an artistic way; the second is just wrong.
I had to play with filters. I used the Fantasy setting, which apparently always photobombs with a dragon. I tried other prompts with this setting, and there’s always a damn dragon in the background. I don’t recall what I used for the fourth picture (I think Pixel Art?), but everything else about it came out rather nicely. If a peaceful village had a lovely, tall woman like this stomping around, I don’t think anyone would mind.
Lisa AI produces huge images for your enjoyment, at 1728×2112, and that’s incredible, on par with BlueWillow’s huge image files. There are lots of other filters, and they cram whatever you’re asking for into their own rigid parameters, which can be useful or annoying. Summer always puts you on the beach or with a beach umbrella. Super Heroes makes your subject bulge with muscles, over a background of lightning and fire. Gothic gives you tattoos and makes you look vampiric (didn’t try the Vampire setting). And Anime… apparently Lisa AI stocked its stores with Sailor Moon to the exclusion of any other title or example. Not great.
AIBY
When you search for AI engines in the Android app store, among the first hits you get are Lisa, Wonder, and this one, so I had to try it out. The ratings for any of these aren’t great, but they’re rated low by users complaining about how many ads you have to see and how their cheap-ass phone konks out midway through a render. OTOH, many AI apps are artificially rated highly because they promise free credits if you give them five stars, and that’s fucking manipulative.




As with all the others, AIBY struggles to comprehend what a giantess might look like. We see the same problem with plasticene miniature sets, but then (maybe I applied a fantasy filter) we get what looks like a large woman in (male gaze) warrior clothing, standing outside a medieval-looking town. Not definitive but pretty good. And then it produced a very tall woman, albeit badly deformed in places, romping through the streets of a village, meeting almost all the parameters of the prompt recipe. Doesn’t look breathtaking but it did many things well. It puts out small images, at 512×512, which is on the lower end of standard product. I’ve canceled my free trial immediately, however. AIBY doesn’t seem to do well with other prompts I’m running, either.
Jasper
All right, I caved. I was poking around, looking for AI art engines, and I found Jasper and wanted to see if I could get free images. I couldn’t without starting an account, and I had too many options to explore first. But now I’m scraping and decided to give Jasper a try. Started an account, signed up for five-day trial, ran some images, and then canceled immediately. You can see why.




It’s that same plasticene miniature effect. Why do so many AI engines default to this? I never said “clay” or “sculpture” or “diorama,” yet this is a fundamental assumption shared by so many of the better programs! Why? Does “tiny” suggest an elementary school art project? Anyway, Jasper doesn’t know what to do with the prompt “giantess” either. You can see some slightly taller-than-average women in some of these images, but what, seven feet tall at most? Bah.
I put Jasper through the paces, tried some other standard prompt recipes I like, and it was slightly less than average on creating a watercolor portrait of a beautiful woman, performing the watercolor effect not at a skilled level and featuring deformed arms at times. And yeah, since this was a personal account not shared by a community, not like Discord or something, I tried some NSFW commands. It terminated explicit prompts immediately, and when I prompted a named celebrity, it claimed its databases had never heard of her. Two important fails in my book. Even when I used one of its own sample prompts, for a Bangkok night market lit by paper lanterns, the output was blurry, malformed, and imprecise. This program has nothing to offer me.
Maze Guru
I heard about Maze Guru because one of its users saw me on NightCafe and sent me an invite to their Discord server.
Then five more people kept inviting me, all begging my pardon, all not trying to be rude, all excusing their behavior because they’re racing for some kind of prize for recruitment on Maze Guru. A predatory server doesn’t look good, Maze Guru.
Anyway, I tried the program with my standard text, no adornments or modifications.



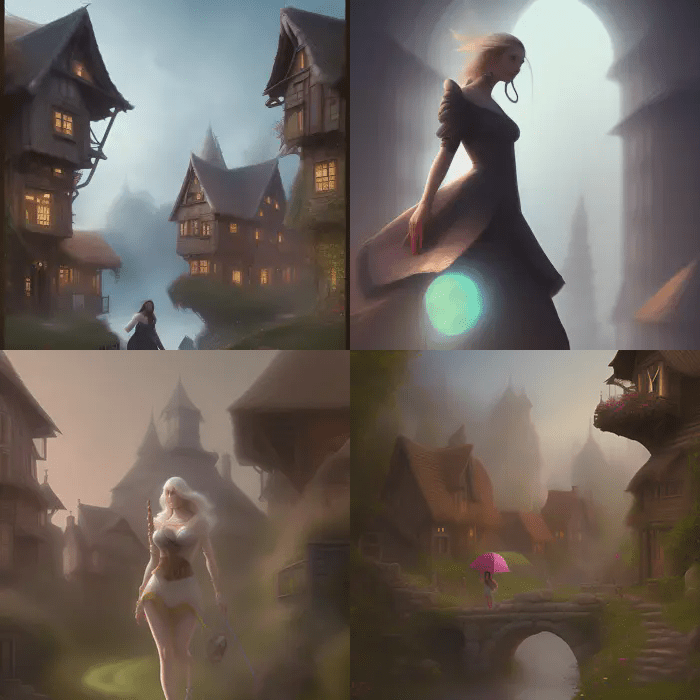
It didn’t really know what it was doing. I don’t know how I got the dreamy effect in the first picture (and the collage of four images beneath it). I didn’t specify it, it just happened. The second image was a different day, using the isolated prompt I used for all of these programs. The third image, okay, I used their “anime” filter, and it produced some more attractive images but nothing really suggestive of a giant woman.
Maze Guru is free, you can play with it, but if you want to download large image files from what you’ve created, a suspicious pop-up appears, asking for access to your Discord account. Take your chances with that if you like; I didn’t, and I’m stuck with these crappy small images.
Adobe Firefly
Adobe has of course created its own art generator. Perhaps any organization that works with images and creative content must feel pressured to join in the fray. Without any modification or altering filters, I put in my standard prompt and let it run.




Note that Adobe is careful to attach its credentials, both so you know where the image came from and so it can track where the images are being used. In that sense, they’re less laissez-faire than… all other art generators.
Firefly produces nicely large images, 2048×2048! They’re generous in that respect, but I suppose with their resources they can afford to be. I don’t know what they’re using for reference material (I never do), but it mostly has an innate grasp of what a giantess is. It seems to believe that a large human must necessarily be burly, even muscular. I don’t know what’s up with the horns and fur—perhaps it’s conflating with other mythical beasts? And this sample included what looks like two giants, rather than female-presenting giantesses, but perhaps they’re gender-fluid, or else Adobe’s pulling from an ambiguous definition of any large general person.
All that aside, I have to consider these results a success. I look forward to attempting to refine the results.
Honorable Mentions
Novel AI: You have to purchase credits to use it, with no freebies or practice.
LAION: You can download and run this for yourself, if you have those coder skills.


Leave a comment